Una storia fatta di deadline, disperazione ed un pizzico di SQL. Con un' amara lezione alla fine.
Questa è una piccola storia ed una lezione che dovrò ricordare per il resto della mia vita. Situazione: sto lavorando ad un database per un mio esame universitario, sia a circa un giorno dalla data di consegna, tutto è perfetto, il database funziona senza alcun errore, tutti i trigger funzionano e le funzioni sono perfette, considerando i dati di prova (circa 3 record per tabella) che avevo fatto a mano, ricevo dalla mia compagna i dati da dare in pasto al database, tutto sembra andare alla grande
Apro il mio browser ed apro Google Fogli (di per sè una buona web app) e scarico il file TSV (Valori separati da tabulazioni) generato. Faccio un source del file sql e non sembrano esserci errori, do un bel "SELECT * FROM Sede;", tutto funziona. Faccio una seconda prova con "SELECT * From Dipendente;" e questo accade:
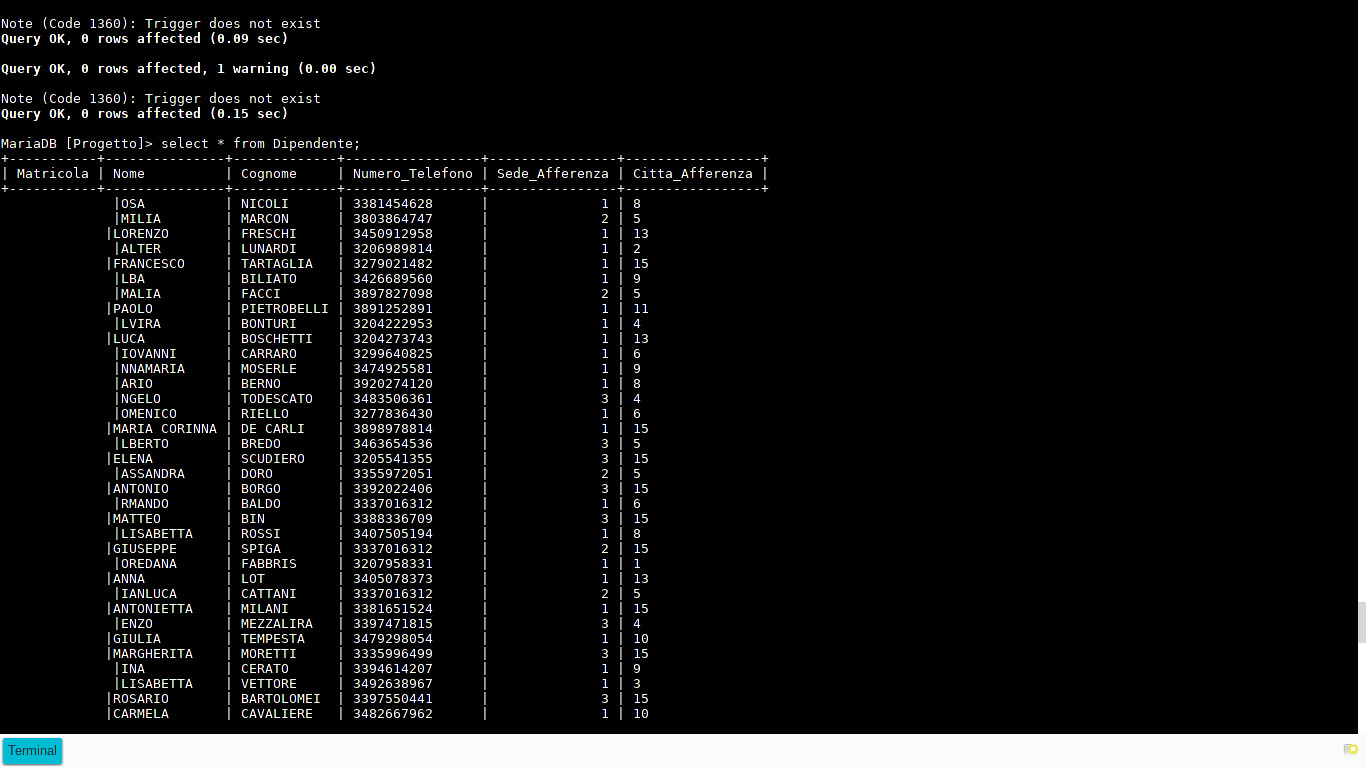
Un pochino sorpreso decido di dare un'occhiata ai dati generati, tutto sembra in ordine.
Mezz'ora se ne va senza alcun progresso, quindi decido di mostrare solo alcune colonne dei dati tramite il comando "SELECT Matricola FROM dipendente;" e la colonna si mostra tranquillamente. Ancora più stupito, continuo le mie ricerche, e dopo un'ora dall'inizio di questo incubo riesco ad isolare il problema: è l'ultima colonna della tabella; ma non sembra che mi stia avvicinando alla soluzione. Un po' di sudore si può intravedere sulla mia fronte.
Avvio nuovamente il mio fidato editor di testo (NeoVIM) ed uso ":set list" per vedere se vi sono caratteri (non visibili) estranei all'interno del file. Niente.
Arrivo ad un'ora e mezza, ed inizio ad arrabbiarmi. Provo soluzioni come aggiungere "FIELDS ENCLOSED BY " ' "; " ma ciò non fa altro che rendere la situazione peggiore, con MariaDB che mi tira addosso 400 warnings, tutti che mi dicono che i dati erano stati tagliati perchè troppo grandi, oppure che vi erano troppe colonne nel file, rispetto al numero di colonne della tabella nel database.
Si arriva a 2 ore, e sono completamente spiazzato, non faccio nemmeno ulteriori ricerche su questo problema. Mi sono arreso al pensiero che non sarei stato in grado di consegnare il progetto e che mesi di lavoro, più altri mesi per attendere la prossima sessione d'esame, fossero persi. Ero disperato, colpendo il mio tabvlo dalla frustrazione ogni qualvolta una soluzione che provavo non funzionava.
Poi per qualche ragione, senza nemmeno rendermene conto, ho cercato su Google "Line Terminators" (Terminatori di Riga) e noto una cosa:
- Linux/Unix usano un carattere (conosciuto come "\n") per dire che una linea è terminata e di andare a nuova riga
- Windows usa una serie di due caratteri ("\r\n") come terminatori di linea
Arrivato a 2 ore e mezza, in uno stato semi-catatonico stile zombie, aggiungo le parole magiche: LINES STARTING BY ''' TERMINATED BY '\r\n';
Faccio il source del database per (penso) la 50esima volta, ed impaurito inserisco la query: "SELECT * FROM Dipendente;"
Tutto funziona. Sono in lacrime, nessun warning per quella tabella, ho vinto.
Decido di prendere tutti i dati e passarli attraverso dos2unix, così da cambiare i terminatori di linea.
Non so come, ma sono riuscito a risolvere un problema disastroso, dato dal fatto che alla fine di una riga vi erano due caratteri invisibili invece di uno.
Sia stato intervento divino, qualche "cassetto della memoria", ma questo mi ha risparmiato con molta probabilità, mesi di università.
Cosa da notare è che, usando Google Fogli per scaricare un file TSV da una macchina Linux, ricevo un file con terminatori di linea di Windows.
Anche se assumessimo che i file TSV fossero originariamente concepiti per il solo uso su Windows, perchè MariaDB su Linux perde la testa per caricare tali files senza un'impostazione specifica?
Questo è qualcosa che onestamente non capisco.
Grazie a tutti per aver letto, i migliori auguri a tutti. Buona giornata.